‘인지’, ‘추론’, ‘수행’이라는 자율주행 시스템 3단계 중 각종 센서를 기반으로 한 ‘인지’ 부분은 기술 발전에 따라 레벨5 구현에 문제가 없을 전망이다. 다만, 「추론」부문에서 아직 많은 발전을 필요로 하고 있다.
지금까지 자율주행 시스템이 사용하는 AI 추론 방식은 딥러닝(Deep Learning)을 기반으로 한다. 기존 머신러닝(Machine Learning)과 달리 딥러닝은 축적되는 데이터의 양에 따라 정확도가 향상된다. 따라서 딥러닝 기반의 AI는 Coding을 잘하는 것이 중요한 것이 아니라 훈련에 사용할 데이터를 수집하는 작업이 가장 중요하다.

사진: AndrewNg
흔히 자율주행 기술력, 경쟁력을 말할 때마다 누적된 테스트 주행거리가 사용된다. 이는 주행거리가 데이터 수집량에 비례한다고 생각하기 때문이다. 테슬라(Tesla)도 자사 차량을 통해 OTA(Over-The-Air)로 주행 데이터를 수집하고 있다. 테슬라의 자율주행 기술력에 대한 높은 평가도 딥러닝 경쟁력에 기인한다.

사진: Tesla
하지만 딥러닝의 한계는 명확하다. 외부 환경을 샘플링한 데이터로 학습하는 방식은 인간의 추론 방식과 비교했을 때 근본적인 차이가 존재한다. 딥러닝은 한 번도 경험해 보지 못한 새로운 데이터에 대한 판단이 불가능하다. 반면 인간은 전혀 경험해 보지 못한 새로운 상황이 눈앞에 놓여도 상식적인 추론(reasoning)이 가능하다.
자율주행 AI는 90% 이상의 익숙한 환경에서는 어쩌면 인간보다 안전한 주행이 가능할 수도 있다. 하지만 데이터 수집이 아직 이뤄지지 않은 나머지 상황에 대해서는 제대로 판단하기 어렵다. 주행 상황에서의 판단 실수는 치명적인 사고로 이어지기 때문에 완벽성을 기해야 하지만 이처럼 특별한 경우의 데이터까지 모두 학습하는 것은 현실적으로 불가능하다.
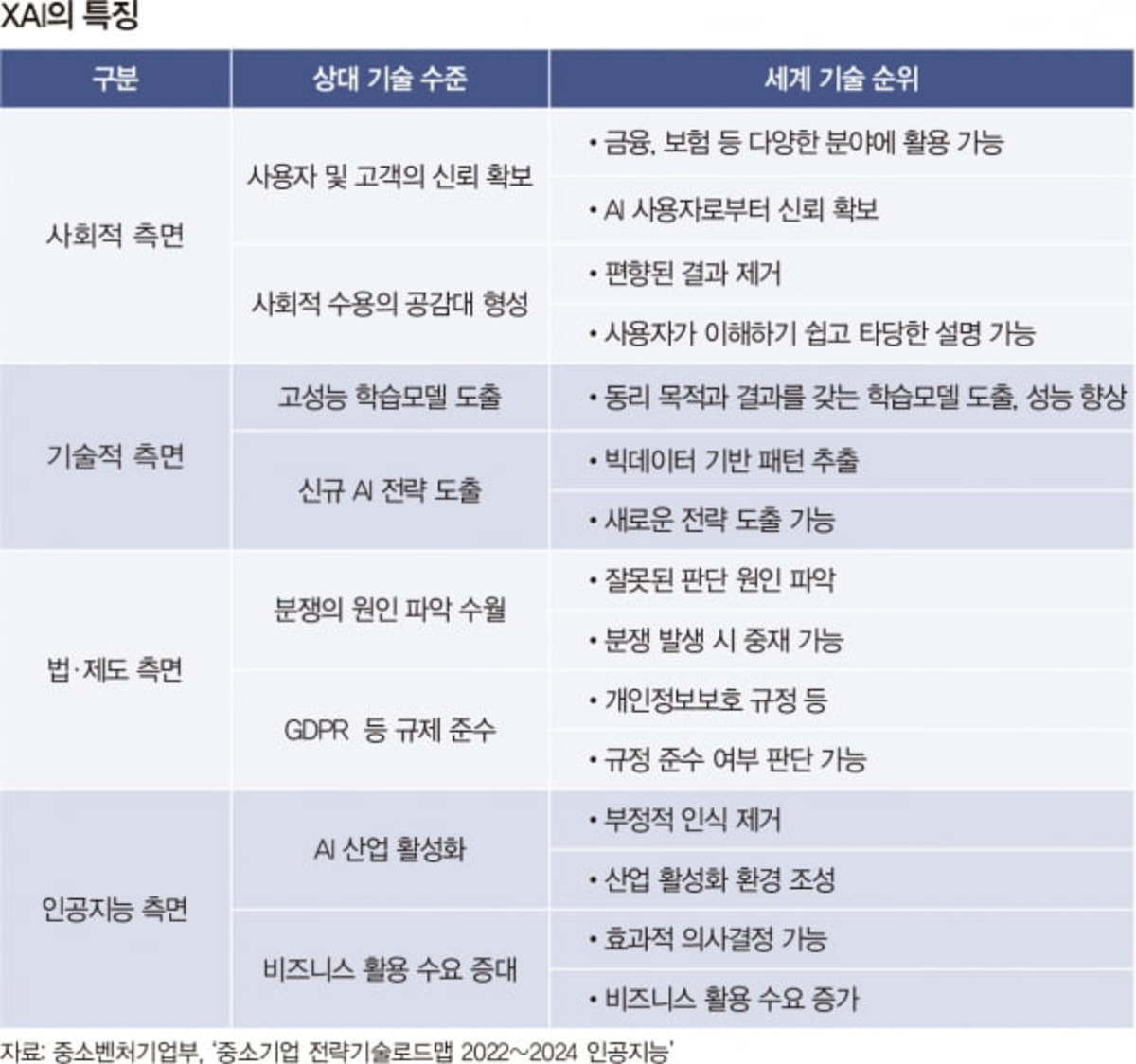
사진: Berkeley
이런 롱테일(Long-tail) 영역의 사례는 사실상 무한대다. 2016년 테슬라 사망사고는 좌회전하고 있는 흰색 트레일러를 인지하지 못하고 하늘로 착각해 그대로 충돌한 사례다. 2018년에는 도로에 비스듬히 서 있던 소방차를 인식하지 못하고 충돌했다. 흰색 복선을 응용한 표지판으로 소금을 뿌려두면 그 안에 갇혀 나올 수 없게 되는 실험 결과도 있다. 이처럼 한 번도 본 적이 없는 경우에 대해서는 대응이 불가능하다는 점이 딥러닝의 한계다.
테슬라는 이들 ‘Edge Case’에 대한 데이터를 지속적으로 학습해 업데이트하고 있다. 그러나 이런 경우가 무한대인 것이 문제다. 테슬라가 99% 자율주행까지는 누구보다 빠르게 도달할 가능성이 높지만 완전 자율주행 도달까지는 자율주행 AI 기술 개선 내지 구현 방식의 근본적인 변화가 필요할 수 있다. 이는 딥러닝이 풀어야 할 숙제다.
결국 학습하는 것이 아니라 생각하는 AI로의 발전을 기대하거나 차량 간 통신 활용이 가능해지면 자율주행의 완전성이 보완될 것으로 판단한다. 테슬라 사고 사례의 경우에도 AI가 트럭을 추론하는 데 실패했더라도 트럭과 차량의 통신이 가능했다면 사고를 피할 수 있었을 것이다.


사진: Teslarati
차량과 차량(V2V), 차량과 인프라 간(V2I) 양방향 통신으로 정보를 교환 및 공유하는 지능형 교통체계를 C-ITS(Cooperative Intelligent Transport Systems)라고 한다. 이는 향후 스마트시티 구축의 근간이 되는 기술이고 유틸리티 성격이어서 공공 주도로 확충해야 할 체계다.
C-ITS는 기술적으로 WAVE 계열과 C-V2X 계열 두 계열로 분류되는데, 우리나라의 경우 상용화 용이성 및 실증 경험 측면에서 DSRC 방식이 유력하게 굳어져 있다. 반면 해외의 경우는 DSRC와 C-V2X 방식이 혼재돼 있다. 우리나라는 정부 주도로 2027년까지 주요 도로에 C-ITS 구축을 추진 중이며, 전국 고속도로에는 2025년까지 구축을 완료할 계획이다.
사진: 한국지능형교통체계협회